Feb 9, 2026
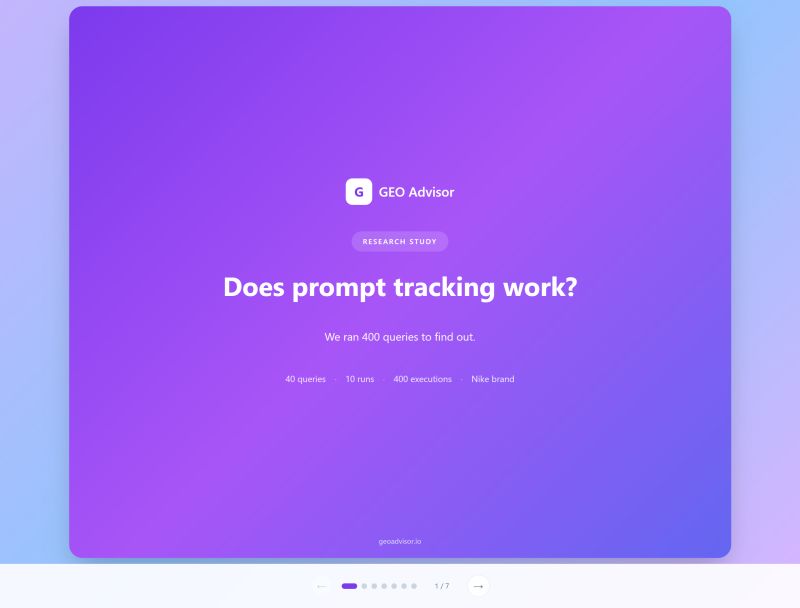
Does Prompt Tracking Work?
A common pushback I hear is this.
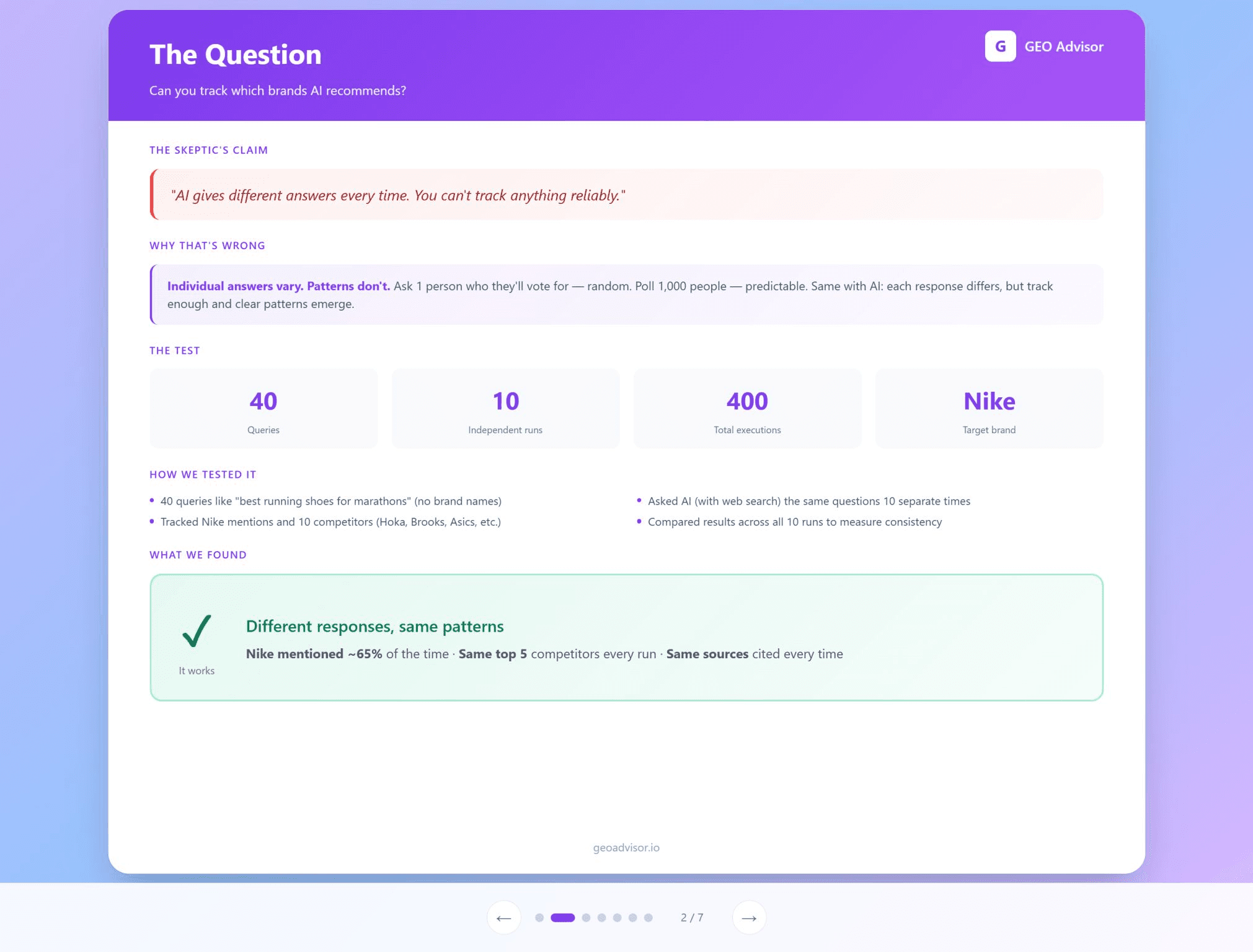
“AI gives different answers every time. You cannot track anything reliably.”
We decided to test that claim.
The experiment
We ran a controlled test to see if patterns hold when you track prompts at scale.
Parameters
40 queries about running shoes, no brands included
Each query run 10 separate times
Tracked Nike and 10 competitors across all responses
400 total model evaluations
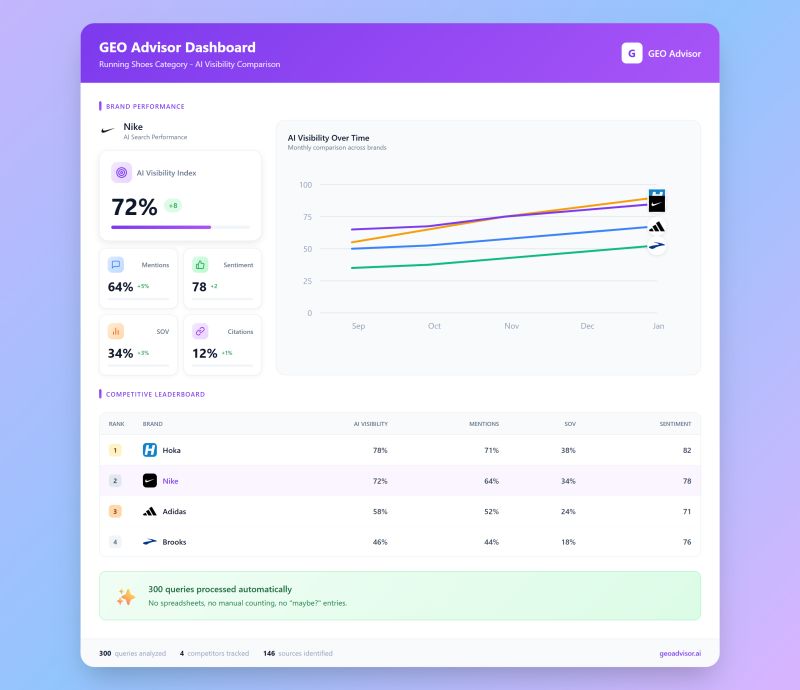
What we found
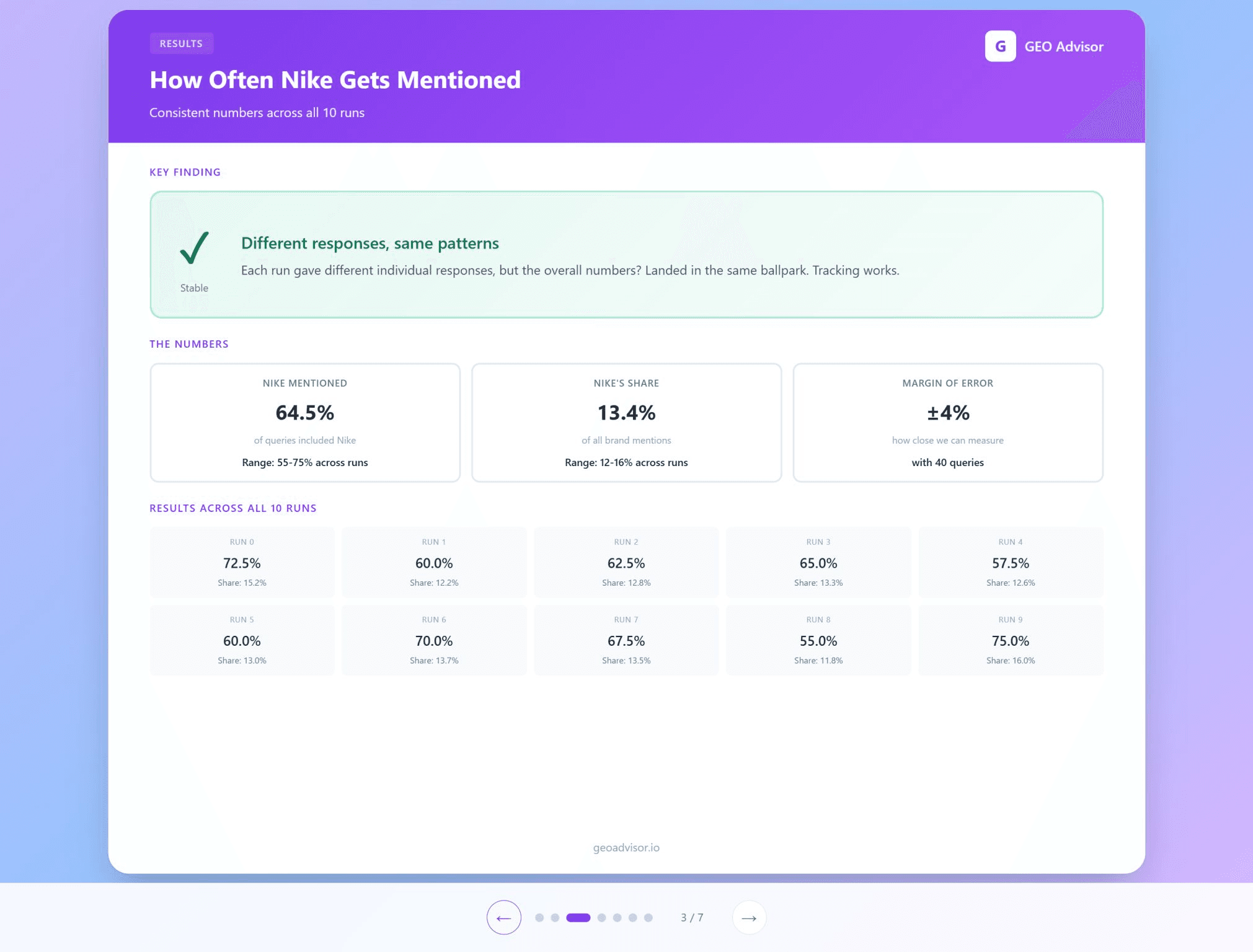
Stable mention rates
Nike appeared in about 65 percent of queries overall. That was not a single extreme result. Across the 10 runs, Nike landed between 55 and 75 percent each time.
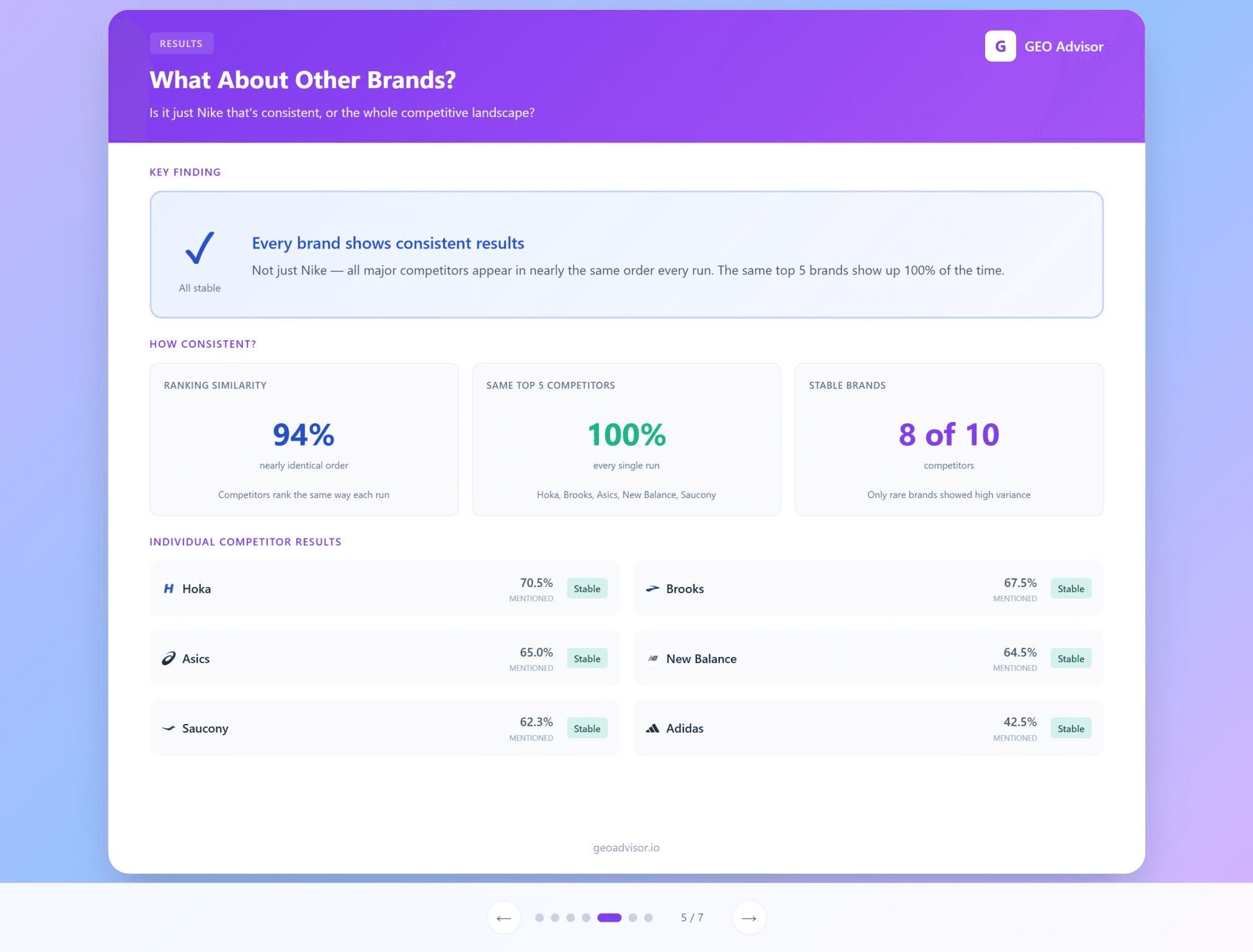
Consistent leaderboards
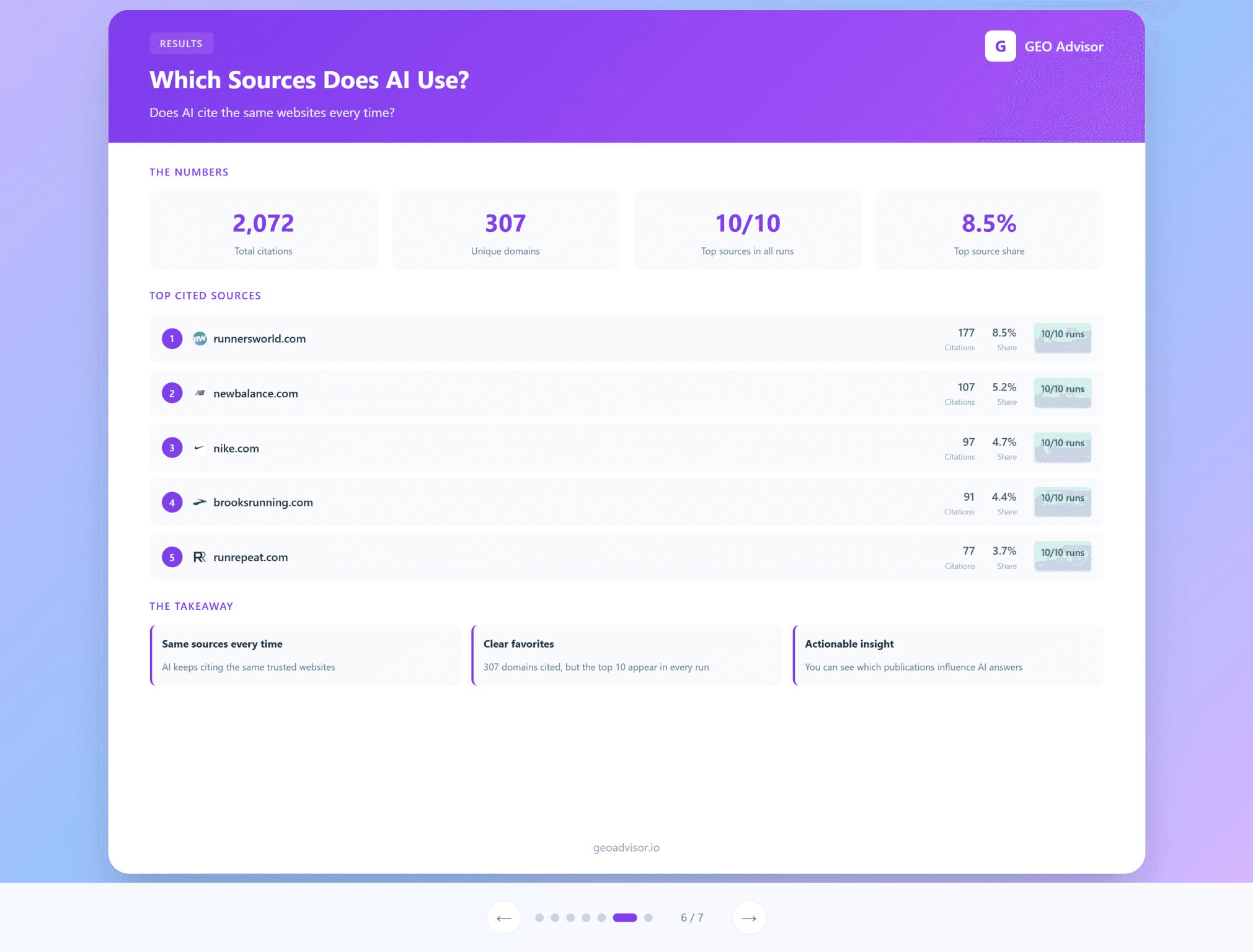
The top five brands were identical in every run. The top 10 sources cited by the model were also stable across runs.
Variation in wording, consistency in patterns
Individual answers varied in tone, phrasing, and detail. The specific recommendations shifted. The underlying patterns did not.
Why this matters
AI responses are non deterministic at the micro level. One answer is noisy. Lots of answers become signal.
Think of it like polling. Asking one person who they will vote for is random. Poll 1,000 people and the distribution becomes predictable.
Prompt tracking works when you treat each response as a sample and measure at scale.
Practical takeaway
If you want to understand how AI models position your brand, do not audit with a handful of prompts and call it a day. Run many queries, track mentions, track sources, and measure leaderboards over time.
Patterns will emerge. Those patterns are actionable.
If you want GEO Advisor to run a prompt stability test for your category, we can replicate this method and show where your brand lands across hundreds of queries.